Viimase paari aasta jooksul on keelemudelitel põhinevad agendid muutunud levinud tööriistaks. Kui keelemudelid 2022. aasta lõpus ChatGPT saabumisega avaliku tähelepanu alla jõudsid, olid nad eelkõige tekstipõhised vestluspartnerid. Sellest ajast peale on mudelite võimekus väliseid tööriistu kasutada järk-järgult arenenud ja tänaseks suudavad mudelid mitmes valdkonnas tegutseda iseseisvate agentidena: otsida veebist infot, kirjutada tarkvaralahendusi ja lugeda dokumente. Allpool käsitleme tehisaruagentide kiire arengu põhjuseid ja uusi ohutusmeetmeid, mida mudelid muutustest tulenevalt vajavad.
2025. aasta alguses avaldas tehisintellekti (TI) hindamisele spetsialiseeruv organisatsioon METR artikli, milles uuriti, kuidas on TI agentide tarkvaraarenduse-alased oskused alates 2019. aastast muutunud (Kwa et al., 2025). Artiklis leiti, et kuue aasta jooksul on agentide võimekus aeganõudvaid ülesandeid lahendada keskmiselt iga seitsme kuu järel kahekordistunud. Näiteks kui GPT-2 lahendas 2019. aastal parimal juhul ülesandeid, millele kulub professionaalsetel arendajatel 3 sekundit, siis GPT-3 lahendas veidi enam kui aasta hiljem edukalt 10-sekundilisi ja GPT-4 2023. aasta märtsis juba 5-minutilisi ülesandeid. Nagu eksponentsiaalsel kasvul kombeks, muutub trend iga aastaga märgatavamaks, sest absoluutskaalal lähevad erinevused suuremaks: kui Claude 3.7 Sonnet suutis selle aasta veebruaris inimesi asendada kuni 54 minutit nõudvatel ülesannetel, siis augustis avaldatud GPT-5 lahendab juba ülesandeid, mis nõuavad asjatundjatelt üle kahe tunni. Teisisõnu, absoluutskaalal on tehisaruagentidele jõukohaste ülesannete pikkus kasvanud viimase kuue kuuga rohkem kui kogu varasema ajaloo jooksul kokku!
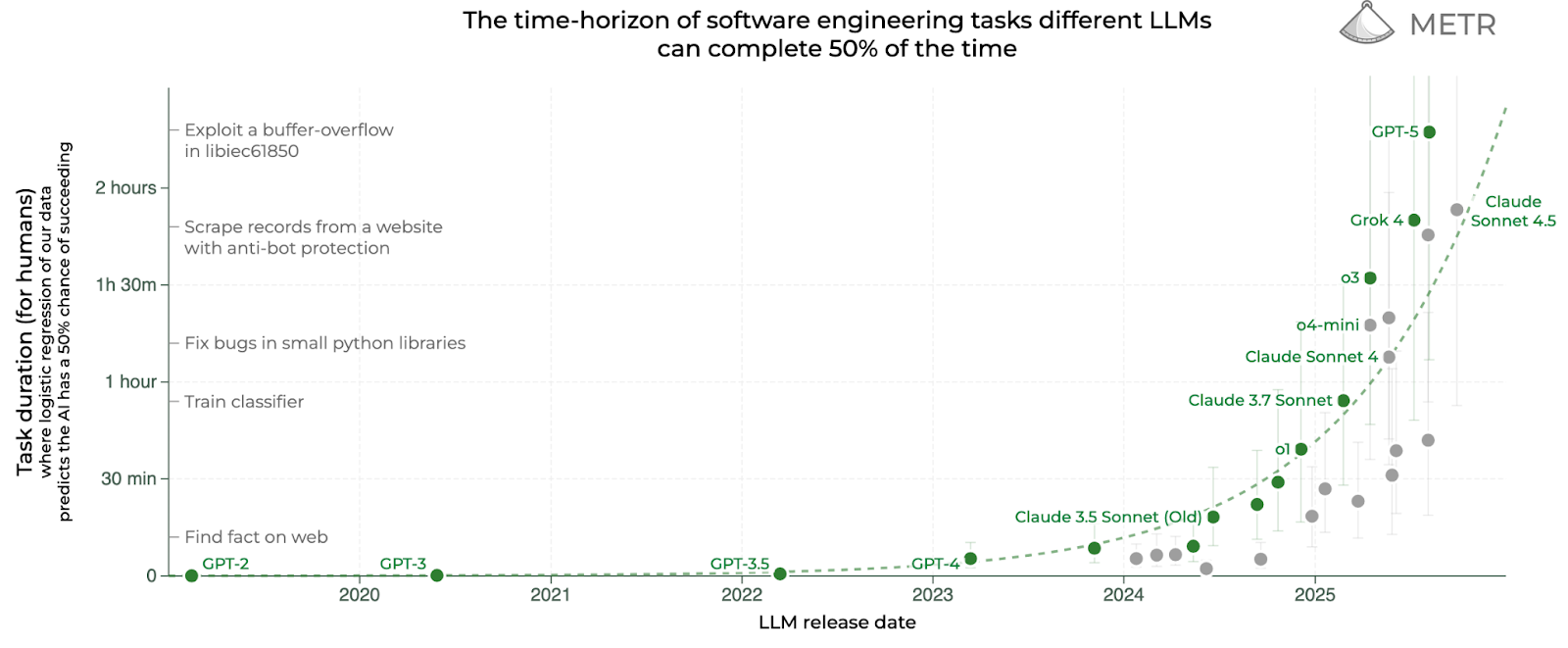
Milliseid arenguid peaksime selle trendi põhjal tulevatel aastatel ootama? METRi trendi võib kõrvutada Moore’i seadusega, mis ütleb, et mikrokiibil olevate transistorite arv kahekordistub iga kahe aasta järel. Samas tuleb muidugi meeles pidada, et kui Moore’i seadus on kehtinud aastakümneid, siis METRi tähelepanekud põhinevad viimase kuue aasta andmetel. Seega on oluline juba lähikuudel jälgida, kuidas uued mudelid trendi mõjutavad – METR uuendab oma veebilehel graafikut jooksvalt.
Võime siiski ennustada, kas trend jätkub lähiaastatel samas rütmis. Selleks tuleb vastata järgmistele küsimusele:
Esimest küsimust on põhjalikult uurinud TI arengu trendidele spetsialiseeruv uurimisinstituut Epoch AI. Epochi hinnangul on TI mudelite treenimiseks kuluv arvutusvõimsus alates 2020. aastast igal aastal viiekordistunud; mudelite treenimiseks kulutatav energiakasutus on samal ajaperioodil igal aastal kasvanud kaks ja pool korda. Ühtlasi on Epochi hinnangul just treeningressursside lisandumine TI hiljutise arengu peamine alustala (Ho et al., 2024).
Suurfirmad püüavad vähemalt lähitulevikus sama tempot hoida: OpenAI plaanib tuleva nelja aasta jooksul taristusse investeerida 500 miljardit eurot (OpenAI, 2025). Selliste trendide jätkumine tähendab aga, et 2030. aastal nõuaks ühe keelemudeli treenimine tänasest maailma SKP-st enam kui ühe protsendi. Seega peab hiljemalt selleks ajaks kas kasv investeeringute suuruses ja mudelite energiakulus märkimisväärselt aeglustuma või peavad TI agendid arengu jätkamiseks ise maailmamajandusse mitmeprotsendilise panuse andma. Isegi viimasel juhul tuleb ületada ka muid tõsiseid takistusi, sealhulgas energia- ja kiipide tootmisvõimsuse piirangud ning treeningandmete nappus (Sevilla et al., 2024). Seega tundub tõenäoline, et kui TI agendid pole 2030. aastaks üldoskuste poolest inimestest võimekamaks saanud, on edasine areng oluliselt aeglasem kui senine areng käesoleval kümnendil.
Kui tõenäoline on, et TI agendid suudavad 2030. aastal majanduskasvu inimestega võrreldava panuse anda? METRi trendi ekstrapoleerides võime oodata, et esimesed mudelid, mis suudavad iseseisvalt kuuajaseid tarkvaraprojekte läbi viia, jõuavad avalikkuse ette vahemikus 2029–2031. Lisaks võime ka hinnata, kui palju TI agendid tänasel päeval arendajate tööd kiirendavad. Selles vallas on hiljutiste uuringute tulemused vastuolulised. METR avaldas juulis artikli, milles leiti, et kuigi arendajate hinnangul muudab TI kasutamine nad oluliselt produktiivsemaks, on nad tegelikult TI tööriistu kasutades 19% aeglasemad kui tavaliselt (Becker et al., 2025). Teisalt raporteeris hiljutine Anthropicu Claude Sonnet 4.5 mudelikaart, et seitse Anthropicu teadlast ja inseneri hindasid oma tööd tänu TI tööriistadele 15% kuni 100% produktiivsemaks (Anthropic, 2025). Mõlemal artiklil on puudusi: METR kogus oma andmed käimasoleva aasta alguses, kui TI agendid olid veel märgatavalt vähem autonoomsed kui täna; Anthropicu mudelikaart toetus aga arendajate endi hinnangutele, mitte kontrollitud uuringutele. Seega on praegu ebaselge, kas ja kui palju tänased TI agendid arendajate tööd kiirendada suudavad, kuid on ka keeruline välistada stsenaariumit, kus mudelid tõepoolest 2030. aastaks inimestest arendajad täies mahus asendanud on.
Ülalkirjeldatud trendidest lähtuvalt on ka TI ohutuse uurijate prioriteedid muutunud. Kui mõni aasta tagasi oli paljude teadlaste eesmärk mudelite kirjeldamiseks teoreetilisi raamistikke luua või neuroteadlase kombel üksikuid neuroneid ja nendest moodustuvaid võrgustikke interpreteerida, siis nüüd on suurem osa kogukonnast seisukohal, et detailsete teoreetiliste raamistike loomiseks pole piisavalt aega – mudelid, mis on võimelised tõsist kahju tekitama, saabuvad liiga kiiresti. Varasemast enam pannakse rõhku väärkasutuse ennetamisele, mudelite mõtteahelate jälgimisele ja üldisele kontrollile, ning mudelite inimväärtustega kooskõlastamisele. Allpool käsitleme neid kolme valdkonda lähemalt.
Agentide kiirest arengust tulenevalt on väärkasutus muutunud pakiliseks probleemiks: parimad keelemudelid on nüüd võimelised pahatahtlikele osapooltele näiteks bio- ja keemiliste relvade loomist märkimisväärselt kiirendama. Näiteks Claude Sonnet 4.5 on inimestest ekspertidega võrreldaval tasemel järgmistes ülesannetes:
Teste, mille abil saab hinnata mudelite võimekust abistada pahatahtlikke osapooli, arendatakse endiselt aktiivselt. Anthropic testis ka näiteks Claude Sonnet 4.5 võimekust vastata küsimustele ohutute bioloogiliste süsteemide ohtlikuks muundamise kohta ja seda protsessi algusest lõpuni autonoomselt läbi viia ning leidis, et nendes ülesannetes jäävad TI agendid inimestest ekspertidele veel selgelt alla (Anthropic, 2025).
Lisaks testide arendamisele prioritiseerivad teadlased väärkasutusest tulenevate ohtude vältimiseks nelja suunda:
Kuigi mudelite kiire areng jätab vähem aega TI ohutuse valdkonna probleemide lahendamiseks, on viimase aasta jooksul kiire arenguga käsikäes käinud ka üks ohutuse vaatepunktist väga positiivne suundumus. Kui varem väljastasid keelemudelid oma vastused mõne sekundi jooksul, siis uusimad mudelid kaaluvad lõppvastuseni jõudmise eel erinevaid lahendusvõimalusi pikas mõtteahelas, tavaliselt inglise keeles:

Taolised mõtteahelad aitavad mudelitel paremaid lõppvastuseid saavutada, millest tulenevalt on loomulik eeldada, et suur osa mudeli lahenduskäigust on mõtteahelas kirjas. Võib loota, et agendi motivatsiooni ja eesmärkide mõistmiseks piisab mõtteahela lugemisest, selmet kasutada keerukaid mudeli sisemiste protsesside uurimise tehnikaid. Seega on viimase aasta jooksul aktiivselt uuritud, kuidas automatiseeritud tööriistade abil mõtteahelates soovimatut käitumist tuvastada.
Kuigi esialgsed uuringud on leidnud, et mõtteahelate lugemisest on mudelite uurimisel ja kontrollimisel palju kasu (Emmons et al., 2025), on mõtteahelate loetavus habras – OpenAI ja Apollo Researchi teadlased on leidnud, et pika stiimulõppe tulemusel võivad mõtteahelad tavapärasest inglise keelest eemalduma hakata (Schoen et al., 2025). Seetõttu on TI ohutusega tegelevad teadlased tuleva aasta uurimiseesmärkideks seadnud nii mõtteahelate loetavuse hoidmise kui ka mõtteahelaid jälgivate automatiseeritud tööriistade arendamise (Korbak et al., 2025).

Võib öelda, et keelemudelid loevad treenimisprotsessi käigus läbi terve interneti, mistõttu on neil mõnes mõttes inimeste väärtustest suurepärane ülevaade. Teisest küljest on mudelite treeningandmetes teksti igasuguste väärtuste esindajatelt ja mudelid oskavad seega täpselt valitud päringute tulemusel jäljendada näiteks nii Toby Ordi kui ka Ted Kaczynski kirjutatud tekste. Seega on mudelite treeningprotsessi üks oluline osa kindlustamine, et mudeli “isiksus” järgiks laia üldsuse eelistusi ja väärtusi.
Kuigi inimtagasisidest lähtuv stiimulõpe, mis on peamine tehnika mudelite inimväärtustega kooskõlla viimiseks, on oma tänasel kujul eksisteerinud aastaid, on viimase aasta jooksul siiski kolmes alamvaldkonnas toimunud olulisi arenguid:
Kui see artikkel tekitas Sinus huvi tehisintellekti ohutuse kohta rohkem uurida, siis järgmised lingid on alustuseks head valikud:
Artiklile andsid tagasisidet Tarmo Pungas, Laura Maria Kull, Mihkel Viires ja Kadi Kaljurand.


